
Auto-exit of Maintenance Mode
Introduction
Auto-exit of maintenance mode is a feature addition to Helix. It concerns a feature that allows clusters to switch out of maintenance mode automatically to save operational costs and to improve availability.
Background
Maintenance Mode
The maintenance mode in Helix refers to a Helix cluster state where the Helix Controller will not trigger any type of rebalance. In short, if a cluster is in maintenance, the Controller will not bootstrap any new partitions. However, this does not mean that there won't be any (upward) state transitions. For example, partitions missing a top-state (e.g. MASTER/LEADER) replica will get a state transition in order to fill in the void for a top-state replica.
Possible Scenarios
There are two possible conditions under which a cluster will go into maintenance mode automatically.
- There are more offline/disabled instances than ClusterConfig's MAX_OFFLINE_INSTANCES_ALLOWED.
- There exist instances that have more partitions than ClusterConfig's MAX_PARTITIONS_PER_INSTANCE.
Difficulty in Manually Exiting Maintenance Mode
Although maintenance mode has been designed to prevent a large-scale reshuffling of replicas when there are intermittent, transient Participant connection issues. When in maintenance, no new partitions will be bootstrapped, which will block many native operations such as creation of stores/DBs. Currently, in order to unblock, an operator must manually disable maintenance mode via Helix REST API. Since it's difficult to predict when temporary disconnects will happen, it has been a challenge to address them in a prompt manner.
Problem Statement
Currently, once clusters enter maintenance mode automatically, exiting must be done manually. This is an added human effort. We want a feature to automate this to reduce downtime and increase availability.
Architecture/Implementation
Maintenance Recovery Threshold
Recall that there are two cases in which a cluster may enter maintenance mode automatically:
- There are more offline/disabled instances than ClusterConfig's MAX_OFFLINE_INSTANCES_ALLOWED.
- There exist instances that have more partitions than ClusterConfig's MAX_PARTITIONS_PER_INSTANCE.
It is important to note that we are mainly concerned with Case 1. Case 2 is meant to be a sanity check against Helix's CRUSH-ed rebalance algorithm, and this has little to do with the original motivation behind cluster maintenance mode. So, although we will still check against Case 2 when determining whether it is safe to exit maintenance mode, we will only address Case 1 in this section.
With that said, it is not hard to imagine a cluster in production experiencing a flip-flop behavior around the exact value of ClusterConfig's MAX_OFFLINE_INSTANCES_ALLOWED field. Such behavior is undesirable and may defeat the purpose of using this feature. To mitigate it in design is to have a separate, more strict threshold for recovering out of maintenance mode. We therefore propose to add a new field, MAINTENANCE_RECOVERY_THRESHOLD. MAINTENANCE_RECOVERY_THRESHOLD will be defined by the user and hold a more conservative value than MAX_OFFLINE_INSTANCES_ALLOWED to allow for some wiggle room in deciding what value is enough to call a cluster “sufficiently recovered”. Additionally, we will also give users the flexibility to “opt-out” of the auto-exit feature by treating a MAINTENANCE_RECOVERY_THRESHOLD value of -1 as a disable signal.
In short,
- If NumOfflineDisabledInstances < NUM_OFFLINE_INSTANCES_FOR_AUTO_EXIT, exit maintenance mode
- NUM_OFFLINE_INSTANCES_FOR_AUTO_EXIT <= MAX_OFFLINE_INSTANCES_ALLOWED
- NUM_OFFLINE_INSTANCES_FOR_AUTO_EXIT < 0 or not set → Opt-out of auto-exiting of maintenance mode
Additional Fields in MaintenanceSignal
Currently, Helix stores the maintenance signal in /{CLUSTER_NAME}/CONTROLLER/MAINTENANCE. A sample maintenance signal ZNode will look like the following:
{
"id" : "maintenance",
"simpleFields" : {
"REASON" : "Offline Instances count 5 greater than allowed count 4. Stop rebalance and put the cluster CLUSTER_TestClusterInMaintenanceModeWhenReachingOfflineInstancesLimit into maintenance mode.",
"TRIGGERED_BY" : "CONTROLLER",
"TIMESTAMP" : "12312838831***",
// The following are sample user-defined fields from the REST call payload //
"id" : "hulee",
"jira" : "HELIX-123",
"cluster" : "testCluster"
},
"listFields" : {
},
"mapFields" : {
}
}
A simpleField will be newly added (notice the “TRIGGERED_BY” field) to denote whether the current maintenance signal has been generated automatically by the Controller. There will initially be two possible entries for this field:
- CONTROLLER
- USER
Also, the TIMESTAMP field will be added so that the value could be retrieved via REST.
In addition, we will allow addition of custom fields in simpleFields. See the example above. Users will be able to add these fields by using the REST endpoints that will be provided when enabling the maintenance mode. Note that when disabling maintenance mode, these fields will no longer be available because disabling maintenance mode will remove the maintenance signal altogether.
Recording Maintenance History
Currently, Helix maintains the controller history in the /{clusterName}/CONTROLLER/HISTORY ZNode. We plan to add a history for maintenance mode. This way, users will be able to access the history in ZooKeeper directly, or utilize the REST endpoint for viewing. The format will be in a human-readable format like the following (this is how Helix maintains the Controller leader history):
long currentTime = System.currentTimeMillis();
DateFormat df = new SimpleDateFormat("yyyy-MM-dd-HH:mm:ss");
df.setTimeZone(TimeZone.getTimeZone("UTC"));
String dateTime = df.format(new Date(currentTime));
Note that Helix only records 10 most recent changes in the HISTORY ZNode. We will follow a similar protocol for persisting maintenance mode-related history. Note that all changes around maintenance mode will be recorded (both entering and exiting of the mode).
Backward Compatibility
Old versions of Helix Controllers will not refer to the newly-added fields, in which case they will simply lack the auto-exit functionality.
Asynchronous Processing
Note that in order for a cluster to exit maintenance mode, the Controller must check against all conditions that are outlined above. That is, it needs to make sure 1) the total count of offline/disabled instances is less than the threshold and that 2) there are no instances with more partitions than the threshold. Checking against Condition 2 requires traversing all resources' states, which could be costly in clusters of large scale. From this, we potentially risk adding a significant latency to the pipeline, which is undesirable because it could cause problems regarding availability (for example, longer pipeline runs may exacerbate the rate at which ZooKeeper Event Callbacks accumulate. Helix currently deals with a large number of ZK Event Callbacks by re-booting the Controller, which could nick Helix's as well as applications' availability numbers).
For this reason, we will make the checks happen asynchronously. Additional tweak may be required to ensure that the maintenance signal is cached appropriately through each run of the pipeline to avoid the race condition.
Periodic Check on Cluster Recovery Status
Auto-exit is inherently triggered as part of Helix's rebalance pipeline; that is, if there is no rebalance triggered, there wouldn't be any auto-exits triggered either. In theory, this is a non-issue because whether a cluster goes into or recovers out of maintenance mode is determined by changes around LiveInstances, and a LiveInstance change is an event that triggers Helix's rebalance pipeline.
Regardless, there has been anecdotal reports where such events seemed to have been “swallowed” or “disappeared” - if that is true for any reason (mostly a ZK callback queue issue), one way to mitigate it is to enable periodically-triggered rebalances. Note that this is actually a feature already supported by Helix.
How to Use the Auto-Exit Feature
Why Use Auto-Exit
Helix is used to manage resources in distributed clusters; therefore, it inevitably gets to have hundreds of instances. With so many clusters and traffic to the ZooKeeper, Helix's metadata store, there are cases in which some Participants in the cluster experience transient connection failure, which may cause Helix to respond to each little change that happens to the cluster. For users of stateful systems, this may be undesirable, so they opt to set a config for entering maintenance mode automatically. Maintenance mode is a temporary mode that the cluster can enter in order to ensure that there are no bootstrapping state transitions on instances.
However, no bootstrapping state transitions could mean that some operations such as addition of resources would be halted, which causes periods of unavailability. It was the cluster operator's responsibility to determine whether the given cluster has sufficiently recovered enough to exit maintenance mode. The auto-exit feature removes such overhead.
Guide
First, we encourage all users of this feature to understand Helix's workflow below:
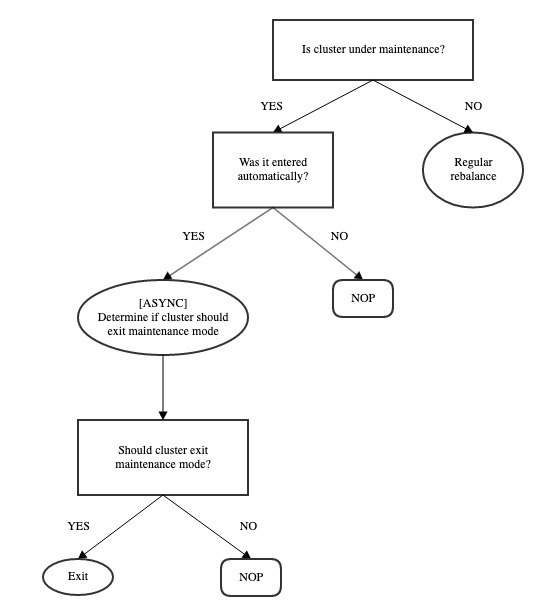
In order to use this feature, you'd need to set the following config parameters in your cluster's ClusterConfig.
Auto-enter maintenance mode
MAX_OFFLINE_INSTANCES_ALLOWED: the number of offline and disabled instances allowed before the cluster automatically enters maintenance mode.
MAX_PARTITIONS_PER_INSTANCE: the number of partitions on any given instance, where, if any instance in the cluster happens to have more partitions than this number, the cluster automatically enters maintenance mode
Auto-exit maintenance mode
NUM_OFFLINE_INSTANCES_FOR_AUTO_EXIT: set this value to allow your cluster to auto-exit when the number of offline and disabled instances are at this value. Note that this value must be less than MAX_OFFLINE_INSTANCES_ALLOWED (Read the design above on why). Note that the appropriate value for this is dependent on the characteristics of the cluster. In general, start with 1, meaning that the cluster will only auto-exit maintenance mode when it is down to 1 offline or disable instance, and increase the value as you increase tolerance.
Note that the cluster will auto-exit only if it has automatically entered maintenance mode previously.
FAQ
How is this related to DelayedAutoRebalancer?
- If you are using DelayedAutoRebalancer for your clusters, this auto-exit feature would still work as expected. Fundamentally, DelayedAutoRebalancer and maintenance mode are mutually independent. That is, under maintenance mode, Helix uses a different rebalancing strategy. Once the cluster auto-exits maintenance mode, it will go back to whichever rebalancing mode it was on previously.
- Delayed Partition Movement is a feature in Helix's FULL-AUTO rebalancer.
- The rebalance delay will work at the instance level and entering/exiting maintenance mode will not affect the time at which the delay-counting started.
How do I know what the appropriate value is for MAINTENANCE_RECOVERY_THRESHOLD?
- As a framework, we cannot provide the right value for this threshold. It should depend on the nature of the application and the risk tolerance thereof. Familiarize yourself with the rules outlined above and start with a low value (for example, 0) and increase your tolerance.