
Helix Tutorial: Customized View
Helix supports users to define their own per partition states that are different from the states appeared in the state model. These states are called customized states. Helix also provides aggregation function for these per partition states across all participants to facilitate the use of them. The aggregated customized state result is called customized view. Usually users would only need to listen on the customized view change to capture customized state updates.
The relationship between customized states and customized view is very similar to that between current states and external view. Helix controller uses similar logic to aggregate external view and customized view. But the two views are designed for different purposes. External view is mainly used to represent Helix state transition status, while customized view is to record users' own state status. This tutorial provides information for users to get started with using customized view, which needs more user input than external view.
The following figure shows the high level architecture of customized view aggregation. 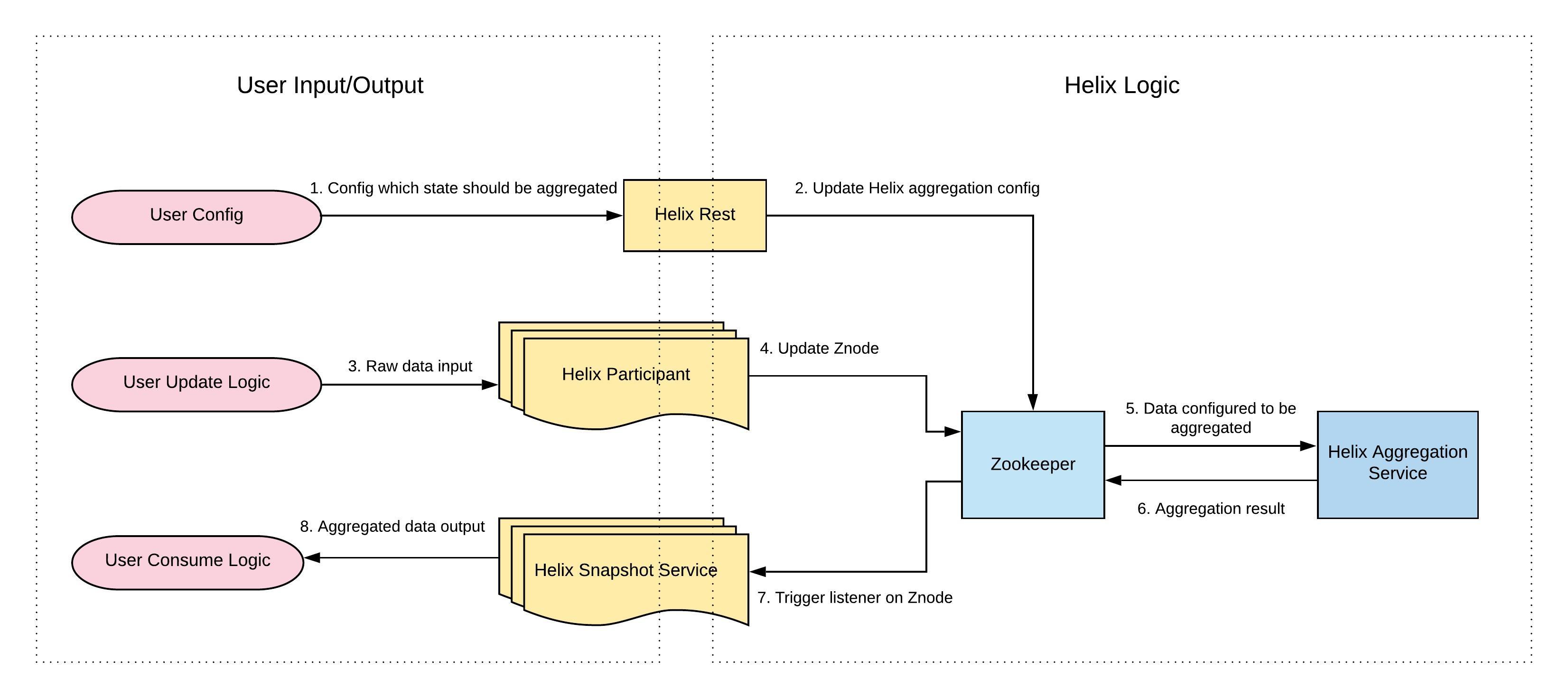
Terminologies
- Customized state: A per partition state defined by users in a string format. Customized state exists under each participant. It may include different types of states. Each type of state is represented as a Znode itself and has different resources as its child Znode.
- Customized state config: A cluster level config specifically used for customized state related config. For example, it can include a list of customized states that should be aggregated.
- Customized view: An aggregation result for customized states across all participants. It exists under the cluster and can also have a few different types of states depending on users' input. Each type of state is represented as a Znode itself and has different resources as its child Znode.
How to Use Customized View
Define Your Own Customized State
Users are responsible for updating customized states in their application code. Helix provides a singleton factory called Customized State Provider Factory, and users should instantiate it if they want to use customized state.
After instantiation, users should call the function in the factory with user defined parameters to build a Customized State Provider object.
There are two ways to build Customized State Provider, and the difference is what kind of HelixManager is passed in. As the following code shows, the first one relies on a Helix provided manager, while the second one needs a user-created Helix manager.
public CustomizedStateProvider buildCustomizedStateProvider(String instanceName,
String clusterName, String zkAddress) {
HelixManager helixManager = HelixManagerFactory
.getZKHelixManager(clusterName, instanceName, InstanceType.ADMINISTRATOR, zkAddress);
return new CustomizedStateProvider(helixManager, instanceName);
}
public CustomizedStateProvider buildCustomizedStateProvider(HelixManager helixManager,
String instanceName) {
return new CustomizedStateProvider(helixManager, instanceName);
}
Helix provides a a couple of functions in Customized State Provider that handle operations such as update, get, delete, etc. The underlying logic is already written in an efficient and thread safe way. Users only need to call these functions to update customized states to Zookeeper whenever they want.
public void updateCustomizedState(String customizedStateName, String resourceName,
String partitionName, String customizedState);
public void updateCustomizedState(String customizedStateName, String resourceName,
String partitionName, Map<String, String> customizedStateMap);
public CustomizedState getCustomizedState(String customizedStateName, String resourceName);
public Map<String, String> getPerPartitionCustomizedState(String customizedStateName,
String resourceName, String partitionName);
public void deletePerPartitionCustomizedState(String customizedStateName, String resourceName,
String partitionName);
Here are some additional guidelines about how to use Customized State Provider:
-
When a user would like to drop a certain instance by calling Helix delete instance API, Helix will delete the instance as well as all sub-paths under it with recursive deletion. Therefore, the customized state will also be deleted, and customized view will be updated when the instance is gone.
-
When a user would like to drop a certain resource by calling Helix delete resource API, he/she will be responsible for deleting customized state of all partitions for that resource across all instances. This operation can be implemented in users' state transition logic.
-
When Helix rebalance happens, and a certain partition on a certain instance is moved to another instance, customers will need to handle the cleanup in the callback function currently provided by Helix in the state transition logic.
-
When an unexpected disconnection happens in client side from Zookeeper, but does not trigger rebalance, Helix will still keep the customized state as it is and wait for the connection to be reset.
Enable Customized State Aggregation in Config
To use Helix customized state and aggregated view, users should firstly call a Helix REST API or a Helix java API to set a cluster level config, called Customized State Config. If users do not config this field properly, they can still use Helix to record their customized states, but Helix will by default skip the aggregation process, as the aggregation will take a fair amount of computing and storage resources. Only when users correctly notify Helix that they want the aggregation by adding the state type in the aggregation config list field, Helix will do the aggregation and output the results to Zookeeper.
There are two ways to update customized state config. One is through JAVA API inside ZK Helix Admin, and the other is through REST API in Cluster Accessor.
The JAVA API provides four different functions as follows.
public void addCustomizedStateConfig(String clusterName, CustomizedStateConfig customizedStateConfig);
public void removeCustomizedStateConfig(String clusterName);
public void addTypeToCustomizedStateConfig(String clusterName, String type);
public void removeTypeFromCustomizedStateConfig(String clusterName, String type);
Every JAVA API has a corresponding REST API. For example, the function addCustomizedStateConfig can be performed by the following REST call.
$curl -X PUT -H "Content-Type: application/json" http://localhost:1234/admin/v2/clusters/myCluster/customized-state-config -d '
{
"id" : "CustomizedStateConfig",
"listFields" : {
"AGGREGATION_ENABLED_TYPES" : ["CUSTOMIZED_STATE_TYPE_0", "CUSTOMIZED_STATE_TYPE_1""]
},
"simpleFields" : {
},
"mapFields" : {
}
}'
Update Consuming Logic to Listen on Customized View Change
The aggregated results is updated in RoutingTableProvider. Users need to properly construct the routing table provider in their consuming logic to use the snapshot that contains customized view. RoutingTableProvider has three different constructors for backward compatibility.
public RoutingTableProvider(HelixManager helixManager) throws HelixException {
this(helixManager, ImmutableMap.of(PropertyType.EXTERNALVIEW, Collections.emptyList()), true,
DEFAULT_PERIODIC_REFRESH_INTERVAL);
}
public RoutingTableProvider(HelixManager helixManager, PropertyType sourceDataType)
throws HelixException {
this(helixManager, ImmutableMap.of(sourceDataType, Collections.emptyList()), true,
DEFAULT_PERIODIC_REFRESH_INTERVAL);
}
public RoutingTableProvider(HelixManager helixManager, Map<PropertyType, List<String>> sourceDataTypeMap) {
this(helixManager, sourceDataTypeMap, true, DEFAULT_PERIODIC_REFRESH_INTERVAL);
}
If users would like to use customized states and customized view, they need to initialize RoutingTableProvider with the last constructor. They also need to define the sourceDataMap. For example, if users would like to listen to both external view and customized view, they can do
Map<PropertyType, List<String>> sourceDataTypeMap = new Hashmap<>();
sourceDataTypeMap.put(PropertyType.CUSTOMIZEDVIEW, Arrays.asList(CUSTOMIZED_STATE_0, CUSTOMIZED_STATE_1))
sourceDataTypeMap.put(PropertyType.EXTERNALVIEW, Collections.emptyList());
routingTableProvider = new RoutingTableProvider(helixManager, sourceDataTypeMap);
Verify Customized View Generated Properly
After finishing all the steps above, users could verify whether the customized view is generated probably based on customized states. For example, if you have two instances: P0 and P1, one resource: MyResource, with two partitions: MyResource_0 and MyResource_1, and each partition has one state in CUSTOMIZED_STATE_TYPE_1, which includes STATE_NAME_0, STATE_NAME_1 and STATE_NAME_2. At a certain time, the customized states may look like something similar to the following.
P0:
{
"id": "MyResource",
"listFields": {},
"mapFields": {
"MyResource_0": {
"CURRENT_STATE": "STATE_NAME_1",
"PREVIOUS_STATE": "STATE_NAME_0",
"START_TIME": "1580221789100",
"END_TIME": "1580221.4.097",
},
"MyResource_1": {
"CURRENT_STATE": "STATE_NAME_2",
"PREVIOUS_STATE": "STATE_NAME1",
"START_TIME": "1580221789880",
"END_TIME": "1580221.4.017"
}
}
}
P1:
{
"id": "MyResource",
"listFields": {},
"mapFields": {
"MyResource_0": {
"CURRENT_STATE": "STATE_NAME_2",
"PREVIOUS_STATE": "STATE_NAME_0",
"START_TIME": "1570221125566",
"END_TIME": "15744432835197",
},
"MyResource_1": {
"CURRENT_STATE": "STATE_NAME_0",
"PREVIOUS_STATE": "STATE_NAME1",
"START_TIME": "1570221723440",
"END_TIME": "1570321.4.017"
}
}
}
After Helix controller aggregation, the customized view should look like the following:
{ "id": "MyResource",
"listFields": {},
"mapFields": {
"MyResource_0": {
"P0": "STATE_NAME_1",
"P1": "STATE_NAME_2"
},
"MyResource_1": {
"P0": "STATE_NAME_2",
"P1": "STATE_NAME_0"
}
}