Architecture
Helix aims to provide the following abilities to a distributed system:
- Automatic management of a cluster hosting partitioned, replicated resources
- Soft and hard failure detection and handling
- Automatic load balancing via smart placement of resources on servers (nodes) based on server capacity and resource profile (size of partitions, access patterns, etc)
- Centralized config management and self discovery, eliminating the need to modify config on each node
- Fault tolerance and optimized rebalancing during cluster expansion
- Management of the entire operational lifecycle of a node. Add, start, stop, enable, and disable without downtime
- Monitoring of cluster health and alerting on SLA violations
- A service discovery mechanism to route requests
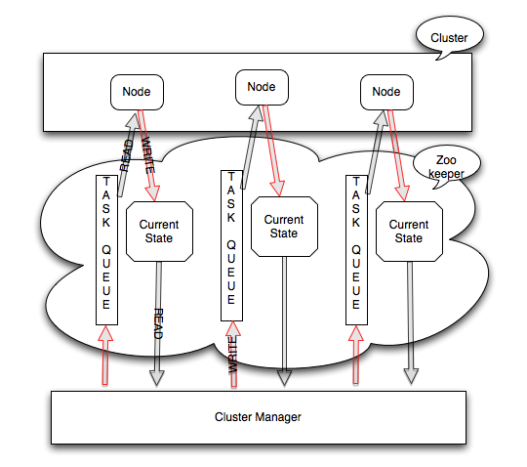
To build such a system, we need a mechanism to coordinate between different nodes and other components in the system. This mechanism can be achieved with software that reacts to any change in the cluster and comes up with a set of tasks needed to bring the cluster to a stable state. The set of tasks will be assigned to one or more nodes in the cluster. Helix serves this purpose of managing the various components in the cluster.
Distributed System Components
In general any distributed system cluster will have the following components and properties:
- A set of nodes also referred to as instances
- A set of resources which can be databases, lucene indexes or tasks
- Subdivisions of each resource into one or more partitions
- Copies of each resource called replicas
- The state of each replica, e.g. Master, Slave, Leader, Standby, Online, Offline, etc.
Roles
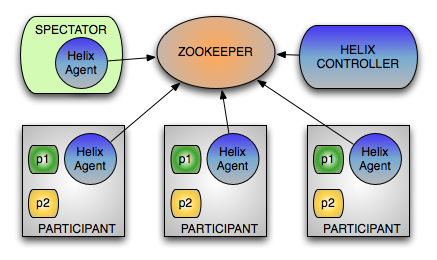
Not all nodes in a distributed system will perform similar functionalities. For example, a few nodes might be serving requests and a few nodes might be sending requests, and some other nodes might be controlling the nodes in the cluster. Thus, Helix categorizes nodes by their specific roles in the system.
Helix divides nodes into 3 logical components based on their responsibilities:
- Participant: The nodes that actually host the distributed resources
- Spectator: The nodes that simply observe the current state of each Participant and routes requests accordingly. Routers, for example, need to know the instance on which a partition is hosted and its state in order to route the request to the appropriate endpoint
- Controller: The node that observes and controls the Participant nodes. It is responsible for coordinating all transitions in the cluster and ensuring that state constraints are satisfied while maintaining cluster stability
These are simply logical components and can be deployed according to system requirements. For example, the Controller:
- can be deployed as a separate service
- can be deployed along with a Participant but only one Controller will be active at any given time.
Both have pros and cons, which will be discussed later and one can chose the mode of deployment as per system needs.
Cluster State Metadata Store
We need a distributed store to maintain the state of the cluster and a notification system to notify if there is any change in the cluster state. Helix uses Apache ZooKeeper to achieve this functionality.
Zookeeper provides:
- A way to represent PERSISTENT state which remains until its deleted
- A way to represent TRANSIENT/EPHEMERAL state which vanishes when the process that created the state dies
- A notification mechanism when there is a change in PERSISTENT and EPHEMERAL state
The namespace provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/). Every node (ZNode) in ZooKeeper's namespace is identified by a path.
More info on Zookeeper can be found at https://zookeeper.apache.org
State Machine and Constraints
Even though the concepts of Resources, Partitions, and Replicas are common to most distributed systems, one thing that differentiates one distributed system from another is the way each partition is assigned a state and the constraints on each state.
For example:
- If a system is serving read-only data then all of a partition's replicas are equivalent and they can either be ONLINE or OFFLINE.
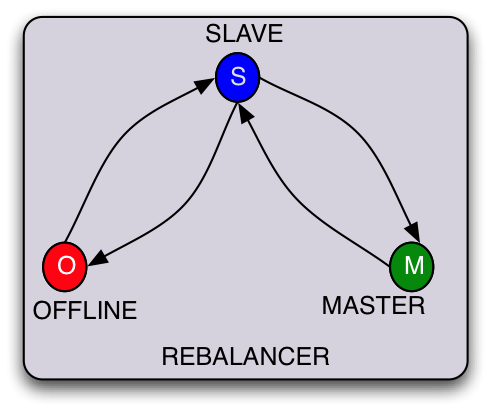
- If a system takes both reads and writes but must ensure that writes go through only one partition, the states will be MASTER, SLAVE, and OFFLINE. Writes go through the MASTER and replicate to the SLAVEs. Optionally, reads can go through SLAVEs.
Apart from defining the state for each partition, the transition path between states can be application specific. For example, in order to become MASTER it might be a requirement to first become a SLAVE. This ensures that if the SLAVE does not have the data as part of OFFLINE-SLAVE transition it can bootstrap data from other nodes in the system.
Helix provides a way to configure an application-specific state machine along with constraints on each state. Along with constraints on STATE, Helix also provides a way to specify constraints on transitions. (More on this later.)
OFFLINE | SLAVE | MASTER
_____________________________
| | | |
OFFLINE | N/A | SLAVE | SLAVE |
|__________|________|_________|
| | | |
SLAVE | OFFLINE | N/A | MASTER |
|__________|________|_________|
| | | |
MASTER | SLAVE | SLAVE | N/A |
|__________|________|_________|
Concepts
The following terminologies are used in Helix to model resources following a state machine.
- IdealState: The state in which we need the cluster to be in if all nodes are up and running. In other words, all state constraints are satisfied.
- CurrentState: The actual current state of each node in the cluster
- ExternalView: The combined view of the CurrentState of all nodes.
The goal of Helix is always to make the CurrentState (and by extension, the ExternalView) of the system same as the IdealState. Some scenarios where this may not be true are:
- Some or all nodes are down
- One or more nodes fail
- New nodes are added and the partitions need to be reassigned
IdealState
Helix lets the application define the IdealState for each resource. It consists of:
- A list of partitions, e.g. 64
- Number of replicas for each partition, e.g. 3
- The assigned node and state for each replica
Example:
- Partition-1, replica-1: Master, Node-1
- Partition-1, replica-2: Slave, Node-2
- Partition-1, replica-3: Slave, Node-3
- …..
- …..
- Partition-p, replica-r: Slave, Node-n
Helix comes with various algorithms to automatically assign the partitions to nodes. The default algorithm minimizes the number of shuffles that happen when new nodes are added to the system.
CurrentState
Every participant in the cluster hosts one or more partitions of a resource. Each of the partitions has a state associated with it.
Example Node-1
- Partition-1, Master
- Partition-2, Slave
- ….
- ….
- Partition-p, Slave
ExternalView
External clients needs to know the state of each partition in the cluster and the Node hosting that partition. Helix provides one view of the system to Spectators as the ExternalView. The ExternalView is simply an aggregate of all node CurrentStates.
- Partition-1, replica-1, Master, Node-1
- Partition-1, replica-2, Slave, Node-2
- Partition-1, replica-3, Slave, Node-3
- …..
- …..
- Partition-p, replica-3, Slave, Node-n
Process Workflow
Mode of operation in a cluster
A node process can be one of the following:
- Participant: The process registers itself in the cluster and acts on the messages received in its queue and updates the current state. Example: a storage node in a distributed database
- Spectator: The process is simply interested in the changes in the ExternalView.
- Controller: This process actively controls the cluster by reacting to changes in cluster state and sending state transition messages to Participants.
Participant Node Process
- When the Participant starts up, it registers itself under LiveInstances
- After registering, it waits for new messages in the message queue
- When it receives a message, it will perform the required task as indicated in the message
- After the task is completed, depending on the task outcome it updates the CurrentState
Controller Process
- Watches IdealState
- Notified when a Participant goes down, comes up, is added, or is removed. Watches the ephemeral LiveInstance ZNode and the CurrentState of each Participant in the cluster
- Triggers appropriate state transitions by sending messages to Participants
Spectator Process
- When the process starts, it asks the Helix agent to be notified of changes in ExternalView
- Whenever it receives a notification, it reads the ExternalView and performs required duties
Interaction between the Controller, Participant and Spectator
The following picture shows how Controllers, Participants and Spectators interact with each other.
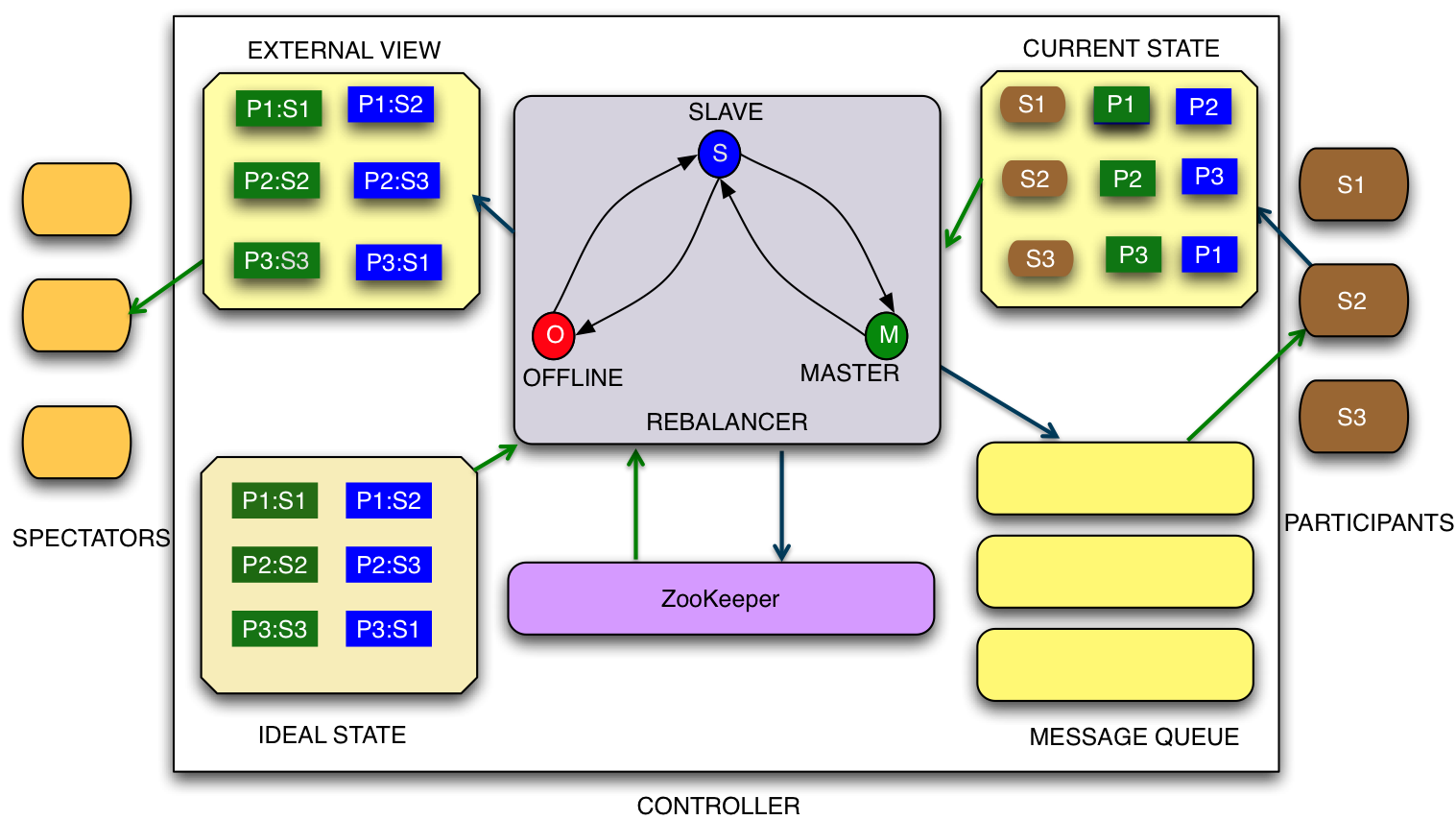
Core Controller Algorithm
- Get the IdealState and the CurrentState of active storage nodes from ZooKeeper
- Compute the delta between IdealState and CurrentState for each partition replica across all Participant nodes
- For each partition compute tasks based on the State Machine Table. It's possible to configure priority on the state Transition. For example, in case of MasterSlave:
- Attempt mastership transfer if possible without violating constraints
- Partition addition
- Partition drop
- Add the transition tasks in parallel if possible to the respective queue for each storage node (if the tasks added are mutually independent)
- If a transition task is dependent on another task being completed, do not add that task
- After any task is completed by a Participant, Controllers gets notified of the change and the algorithm is re-run until the CurrentState matches the IdealState.
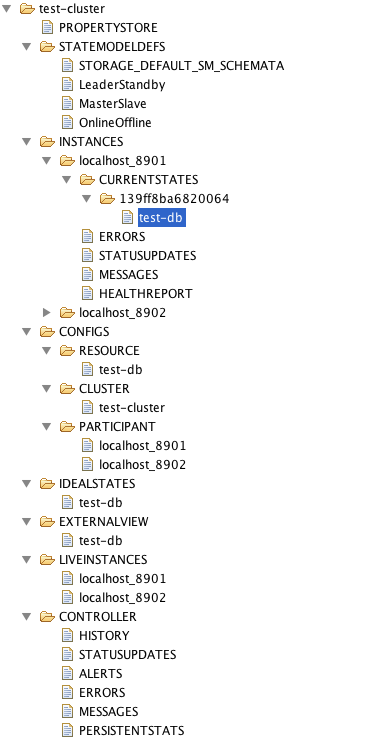
Helix ZNode Layout
Helix organizes ZNodes under the cluster name in multiple levels.
The top level (under the cluster name) ZNodes are all Helix-defined and in upper case:
- PROPERTYSTORE: application property store
- STATEMODELDEFES: state model definitions
- INSTANCES: instance runtime information including current state and messages
- CONFIGS: configurations
- IDEALSTATES: ideal states
- EXTERNALVIEW: external views
- LIVEINSTANCES: live instances
- CONTROLLER: cluster controller runtime information
Under INSTANCES, there are runtime ZNodes for each instance. An instance organizes ZNodes as follows:
- CURRENTSTATES
- sessionId
- resourceName
- ERRORS
- STATUSUPDATES
- MESSAGES
- HEALTHREPORT
Under CONFIGS, there are different scopes of configurations:
- RESOURCE: contains resource scope configurations
- CLUSTER: contains cluster scope configurations
- PARTICIPANT: contains participant scope configurations
The following image shows an example of the Helix ZNode layout for a cluster named “test-cluster”: