1) Add a contribution to the SCA domain
The contribution process is about adding Types to the domain (composites, classes, XSD complexTypes, etc).
1. An SCA application is developed and packaged as a jar or another archive format
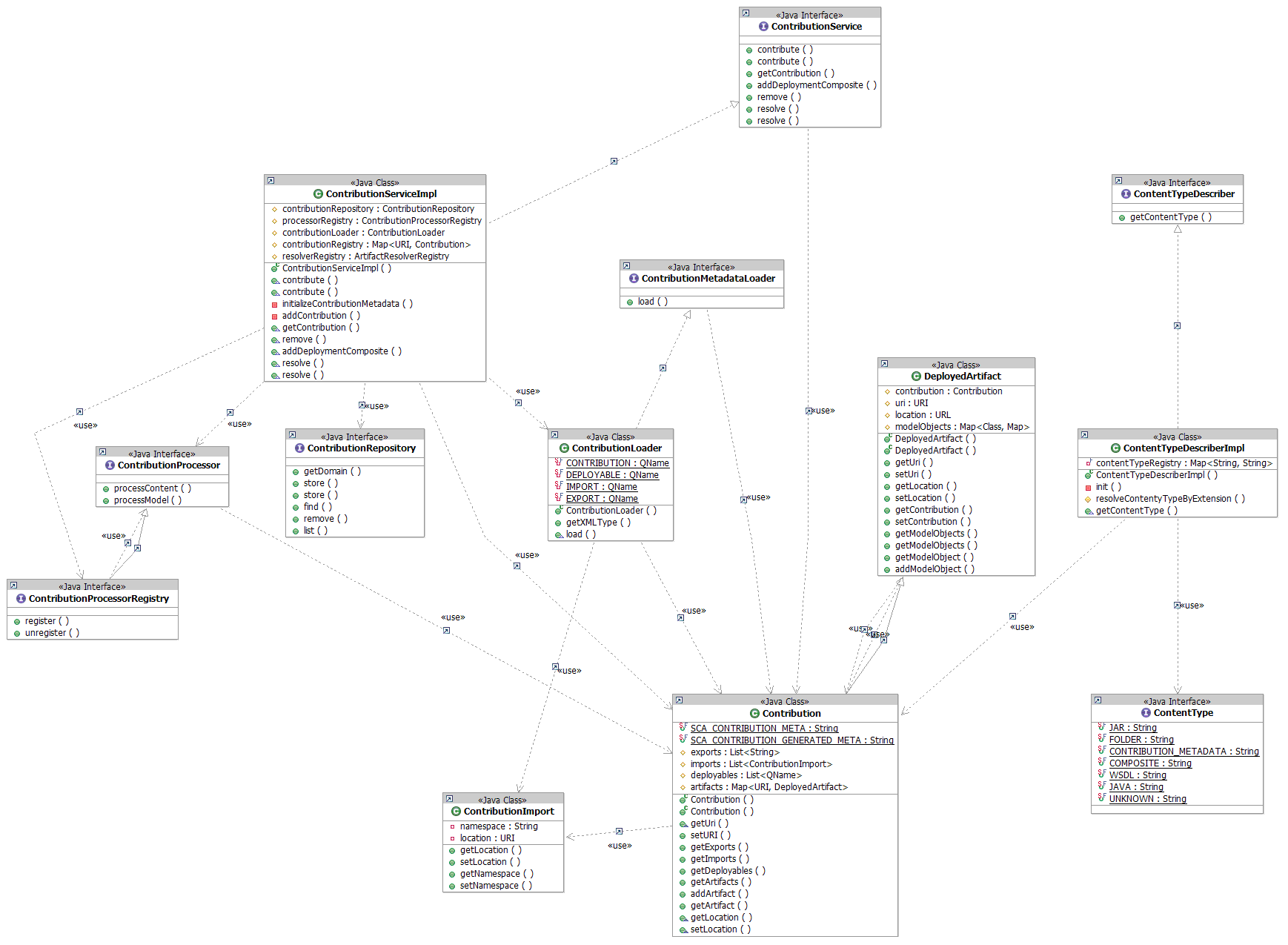
2. The ContributionService is requested to add this jar as a contribution to the SCA domain. In effect, the SCA domain has a store to keep all the contributions. The ContributionService is an API that allows users to put contributions in the store. The contributions are identified by the URI. 3. Registered ContributionProcessor's will be selected based on the contentType of the contribution. The ContributionProcessor is responsible to introspect the contribution which is a collection of artifacts. It may enlist other services to help, e.g the annotation processors for Java classes.We'd support a few well-known types in the core, primarily the ones used by the runtime like "jar" and "java class". Others could be contributed as extensions, e.g "rpm"
 | Introspection of a contribution
In general the result of that introspection would be invariant so it can be cached and replicated in many places. Introspection will be intensive and so we should do it as little as possible and caching the results is good. Of course, we'd need invalidation too.
The caching is about storing the introspection results for "production" artifacts that are basically versioned and immutable. This is similar in concept to the way Maven caches artifacts locally and never needs to go back to an online repo once they have been downloaded. Given some introspections are likely to be expensive (e.g. scanning an EAR to look for EJBs and then processsing the class files for annotations) it would be good to avoid redoing that when its not necessary. |
3. The ContributionProcessor introspects the contribution to create a list of artifacts of interest for SCA. Each artifact is classified by ContentTypes.
4. The artifacts are parsed by the content type. we provide parsers for SCDL (StAXElementLoader) and we can reuse existing parsers for XSD and WSDL (XmlSchema, wsdl4j, woden). So the WSDL introspector would parse the document using, say, wsdl4j and then store the interesting things that it finds.
5. The interesting definitions are added to the contribution store and that is the end of the contribution operation. We keep the contribution and cache the introspection results.
The following diagram is created to illustrate the key players that interacts with the ContributionService.
 | We could merge the ContributionProcessor and ArtifactProcessor concepts into one. If so, the processor for the jar will be called first, it scans the files in the jar and delegate the processors which can handle the content types, for example, WSDLProcessor to load WSDLs, XSDProcessor to load XSDs, JavaAnnotationProcessor to introspect java classes and SCDL loaders to load SCDL files. |
Contribution Services Implementation
The contribution services is available in multiple modules at java/sca/runtime/services
Contribution Modules
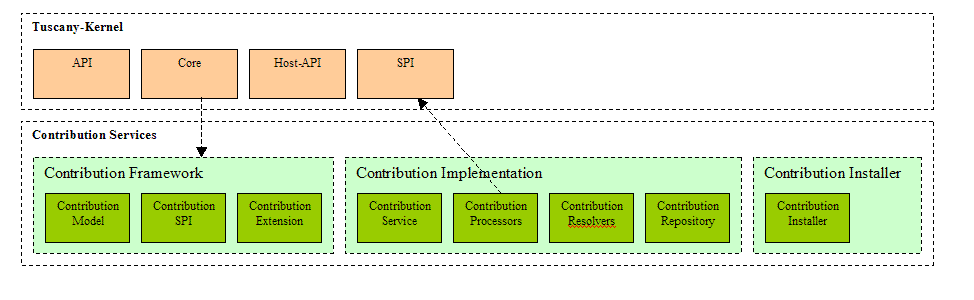
| Note that the Contribution Services Implementation have dependencies on the Kernel SPI
-> LooaderRegistry
-> SCA Model objects
The Kernel will have dependency on Contribution-Framework once things get integrated |
The ContributionService interface
/**
* Service interface that manages artifacts contributed to a Tuscany runtime.
*
* @version $Rev: 523009 $ $Date: 2007-03-27 10:38:24 -0700 (Tue, 27 Mar 2007) $
*/
public interface ContributionService {
/**
* Contribute an artifact to the SCA Domain. The type of the contribution is
* determined by the Content-Type of the resource or, if that is undefined,
* by some implementation-specific means (such as mapping an extension in
* the URL's path).
*
* @param contributionURI The URI that is used as the contribution unique ID.
* @param sourceURL the location of the resource containing the artifact
* @param storeInRepository flag that identifies if you want to copy the
* contribution to the repository
* @throws DeploymentException if there was a problem with the contribution
* @throws IOException if there was a problem reading the resource
*/
void contribute(URI contributionURI, URL sourceURL, boolean storeInRepository) throws ContributionException,
IOException;
/**
* Contribute an artifact to the SCA Domain.
*
* @param contributionURI The URI that is used as the contribution unique ID.
* @param contributionContent a stream containing the resource being
* contributed; the stream will not be closed but the read
* position after the call is undefined
* @throws DeploymentException if there was a problem with the contribution
* @throws IOException if there was a problem reading the stream
*/
void contribute(URI contributionURI, InputStream contributionContent)
throws ContributionException, IOException;
/**
* Get the model for an installed contribution
*
* @param contribution The URI of an installed contribution
* @return The model for the contribution or null if there is no such
* contribution
*/
Contribution getContribution(URI contribution);
/**
* Adds or updates a deployment composite using a supplied composite
* ("composite by value" - a data structure, not an existing resource in the
* domain) to the contribution identified by a supplied contribution URI.
* The added or updated deployment composite is given a relative URI that
* matches the "name" attribute of the composite, with a ".composite"
* suffix.
*/
void addDeploymentComposite(URI contribution, Object composite);
/**
* Remove a contribution from the SCA domain
*
* @param contribution The URI of the contribution
* @throws DeploymentException
*/
void remove(URI contribution) throws ContributionException;
/**
* Resolve an artifact by QName within the contribution
*
* @param <T> The java type of the artifact such as javax.wsdl.Definition
* @param contribution The URI of the contribution
* @param definitionType The java type of the artifact
* @param namespace The namespace of the artifact
* @param name The name of the artifact
* @return The resolved artifact
*/
<T> T resolve(URI contribution, Class<T> definitionType, String namespace, String name);
/**
* Resolve the reference to an artifact by the location URI within the given
* contribution. Some typical use cases are:
* <ul>
* <li>Reference a XML schema using
* {http: * <li>Reference a list of WSDLs using
* {http: * </ul>
*
* @param contribution The URI of the contribution
* @param namespace The namespace of the artifact. This is for validation
* purpose. If the namespace is null, then no check will be
* performed.
* @param uri The location URI
* @param baseURI The URI of the base artifact where the reference is
* declared
* @return The URL of the resolved artifact
*/
URL resolve(URI contribution, String namespace, URI uri, URI baseURI);
}
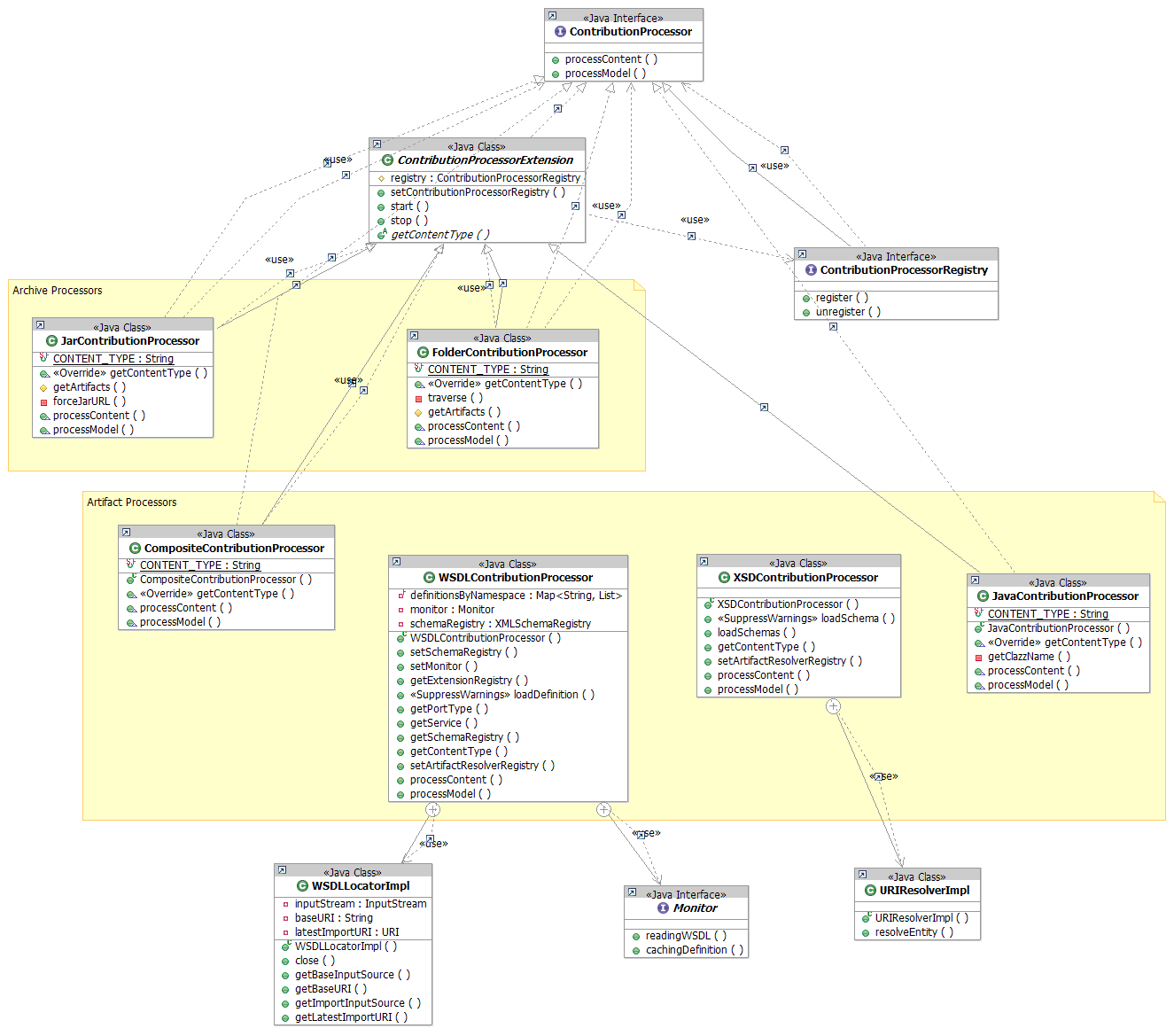
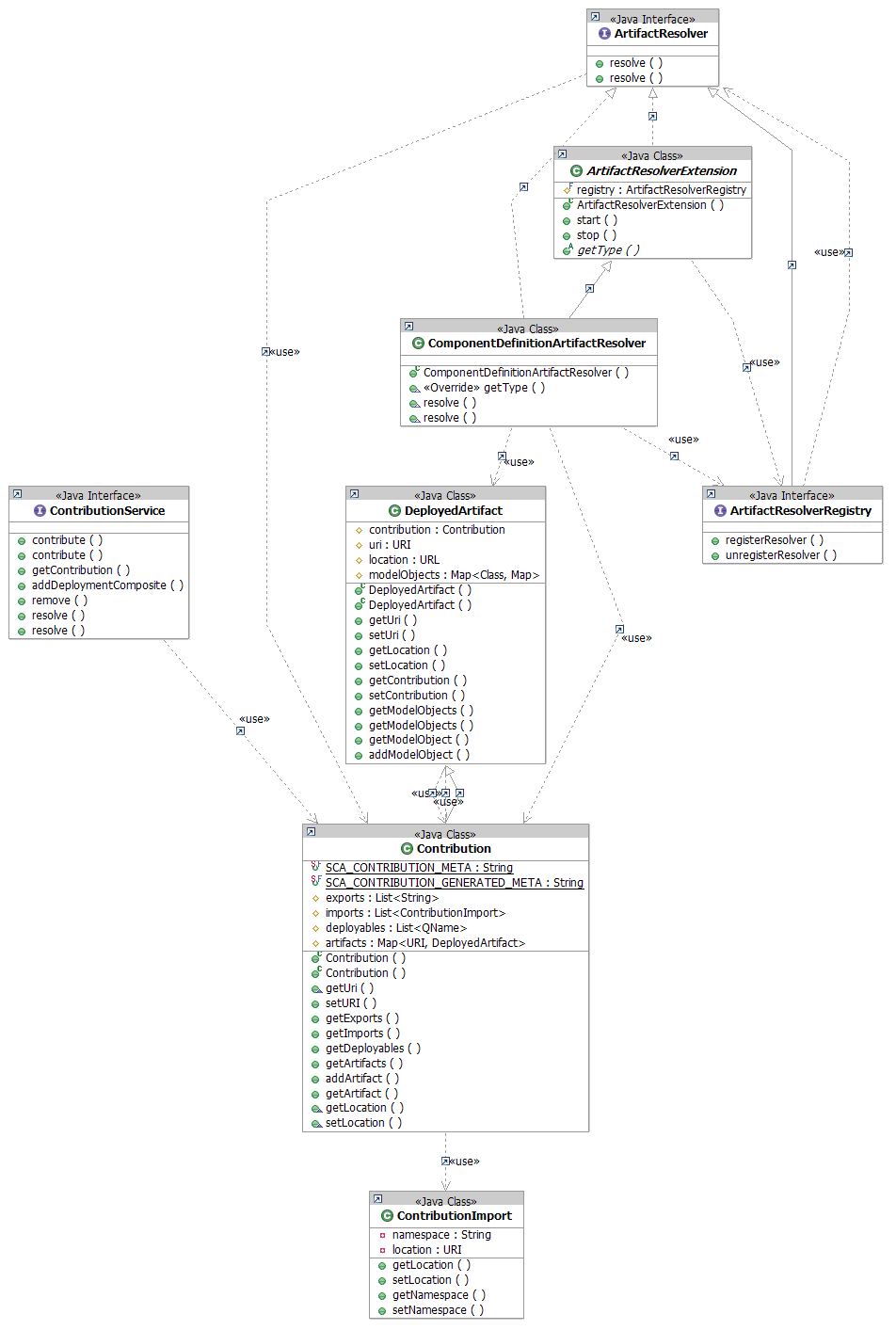
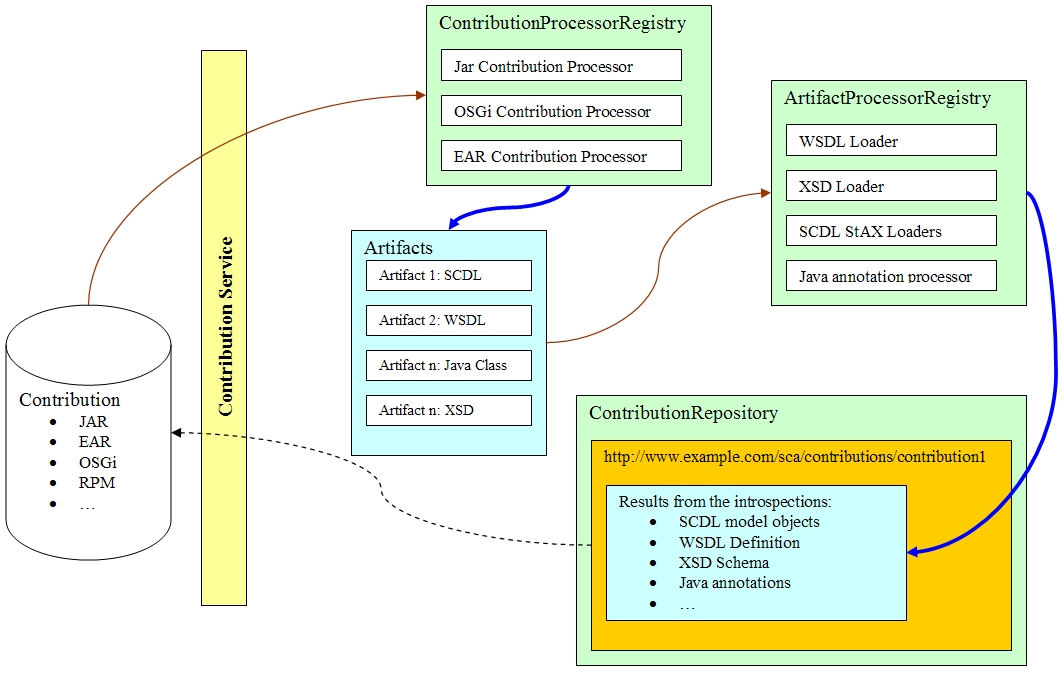
Contribution Services UML Diagrams
Contribution Services
Contribution Processors
Artifact Resolver

2) Apply Changes to the Assembly
The assembly is about creating/modifying/ removing instances of things (primarily components).
1. User calls "addToDomainComosite" or "applyChanges" aginst the AssemblyService. There is a changeSet which represents an atomic modification to the domain, for example, adding an "include" to the domain composite.
2. The assembly service applies this to the current logical assembly creating a new revision of the assembly.
3. The action in the changeSet will need to be expanded out, e.g.
- The <include> will need to be resolved to a composite.
- The content of the composite will need to be examined and result in new components being defined
- Those components will have implementations that need to be run and requirements on where and so forth
There is a resolution phase that is used to build a fully configured logical model where references (things like composite names, class names, etc) are resolved this is done using the contribution service to retrieve the target artifacts for the references. It calls back the contribution service to resolve the cross-references probably via a different api but it is going to the store.So now we have a fully resolved logical configuration model. Errors may be reported during the resolve phase such as:
- No such composite
- No such service
- WSDL portType cannot be resolved
But we also run a logical validation on the resulting model, e.g. checking that if wires connect.
4. Convert the new logical model to a set of physical models which involves allocating pieces of the model to physical runtimes so that they can be consumed by the runtime to activate the components. This is done by creating physical changeSets for each runtime.
5. The physical models are propagated to the given runtime by some means (via the FederatedDeployer suppor that Meeraj's working on)
| Physical models for the runtime
The changeSet for the physical runtime is meant to be very precise and the builder's role is to turn that into runnable code. So it's not SCDL stuff but much lower level. The idea is to keep the builder very simple (and hence quite testable) that means there is a bit more work in the conversion from logical to physical, bascially a "portable" builder.
The conversion will use the introspection results from the store to generate the builder configuration, for example, suppose introspection discovers a component has an @Init method, we store that in the introspection result. The ContributionProcessor might load the java classes to introspect the annotations. (It may not actually load the class using a class loader since it could parse bytecode e.g. with ASM). But the result is an extended implemenation description. We need a langauge neutral form for that so ideally it can be used on both a Java and Native platform. It's something that goes beyond the componentType and it's the PojoComponentType type of thing, but more.
The idea of "portable builders" is about separating the node responsible for domain assembly from the nodes running component implementations. In a heterogeneous federation, it could be the assembly node(s) are running C++ but the user wants to add a Java component that will actually run on a Java node. If the introspection results for the Java contribution are portable, it would be possible for the C++ to set up the physical configuration for the Java builder; alternatively, it could delegate that to a service running in a native Java environment. Similarly, if the component was in some portable language (like Ruby or XSLT), then the configuration could be done on a Java node and passed to a C++ runtime node. |
6. The next steps is the build/connect/run.