Use cases at LinkedIn
At LinkedIn Helix framework is used to manage 3 distributed data systems which are quite different from each other.
- Espresso
- Databus
- Search As A Service
Espresso
Espresso is a distributed, timeline consistent, scal- able, document store that supports local secondary indexing and local transactions. Espresso databases are horizontally partitioned into a number of partitions, with each partition having a certain number of replicas distributed across the storage nodes. Espresso designates one replica of each partition as master and the rest as slaves; only one master may exist for each partition at any time. Espresso enforces timeline consistency where only the master of a partition can accept writes to its records, and all slaves receive and apply the same writes through a replication stream. For load balancing, both master and slave partitions are assigned evenly across all storage nodes. For fault tolerance, it adds the constraint that no two replicas of the same partition may be located on the same node.
State model
Espresso follows a Master-Slave state model. A replica can be in Offline,Slave or Master state. The state machine table describes the next state given the Current State, Final State
OFFLINE | SLAVE | MASTER
_____________________________
| | | |
OFFLINE | N/A | SLAVE | SLAVE |
|__________|________|_________|
| | | |
SLAVE | OFFLINE | N/A | MASTER |
|__________|________|_________|
| | | |
MASTER | SLAVE | SLAVE | N/A |
|__________|________|_________|
Constraints
- Max number of replicas in Master state:1
- Execution mode AUTO. i.e on node failure no new replicas will be created. Only the State of remaining replicas will be changed.
- Number of mastered partitions on each node must be approximately same.
- The above constraint must be satisfied when a node fails or a new node is added.
- When new nodes are added the number of partitions moved must be minimized.
- When new nodes are added the max number of OFFLINE-SLAVE transitions that can happen concurrently on new node is X.
Databus
Databus is a change data capture (CDC) system that provides a common pipeline for transporting events from LinkedIn primary databases to caches within various applications. Databus deploys a cluster of relays that pull the change log from multiple databases and let consumers subscribe to the change log stream. Each Databus relay connects to one or more database servers and hosts a certain subset of databases (and partitions) from those database servers.
For a large partitioned database (e.g. Espresso), the change log is consumed by a bank of consumers. Each databus partition is assigned to a consumer such that partitions are evenly distributed across consumers and each partition is assigned to exactly one consumer at a time. The set of consumers may grow over time, and consumers may leave the group due to planned or unplanned outages. In these cases, partitions must be reassigned, while maintaining balance and the single consumer-per-partition invariant.
State model
Databus consumers follow a simple Offline-Online state model. The state machine table describes the next state given the Current State, Final State
OFFLINE | ONLINE |
___________________|
| | |
OFFLINE | N/A | ONLINE |
|__________|________|
| | |
ONLINE | OFFLINE | N/A |
|__________|________|
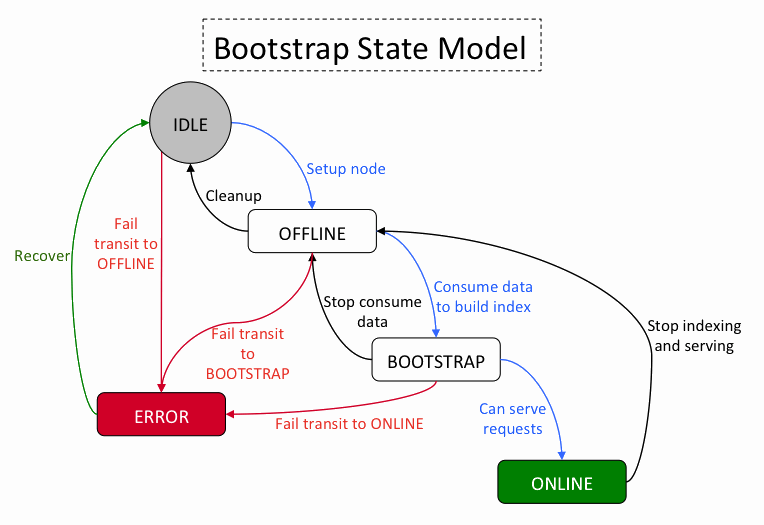
Search As A Service
LinkedIn�s Search-as-a-service lets internal customers define custom indexes on a chosen dataset and then makes those indexes searchable via a service API. The index service runs on a cluster of machines. The index is broken into partitions and each partition has a configured number of replicas. Each cluster server runs an instance of the Sensei system (an online index store) and hosts index partitions. Each new indexing service gets assigned to a set of servers, and the partition replicas must be evenly distributed across those servers.
State model